#Web Scraping News Articles
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Lawyer Data Scraping Services: The Key to Smarter Legal Insights
In the legal industry, access to accurate and updated information is crucial. Whether you're a law firm, researcher, or legal analyst, having comprehensive data at your fingertips can significantly improve decision-making. This is where lawyer data scraping services come into play. These services help extract valuable legal data from various sources, streamlining research and enhancing efficiency.

Why Do You Need Lawyer Data Scraping?
Lawyer data scraping is an advanced technique used to collect information from legal directories, court databases, attorney profiles, and law firm websites. By leveraging this service, you can:
Gather details of legal professionals, including their expertise, contact information, and case history.
Monitor legal trends and analyze case outcomes.
Keep up with changes in law firm structures and attorney movements.
Automate data collection for legal marketing and research.
Key Benefits of Lawyer Data Scraping Services
1. Enhanced Legal Research
Scraping legal data provides easy access to case summaries, judgments, and court filings, allowing legal professionals to stay informed.
2. Competitor & Market Analysis
For law firms looking to stay ahead, scraping lawyer and firm data can offer insights into competitors’ activities, helping refine strategies.
3. Time & Cost Efficiency
Manual data extraction is time-consuming and prone to errors. Automated data scraping ensures accuracy while saving valuable time.
4. Improved Lead Generation
With access to attorney and law firm directories, firms can identify potential clients or partnerships, streamlining their outreach efforts.
Industries Benefiting from Lawyer Data Scraping
Legal Research Firms – Gain instant access to extensive case records.
Law Firms – Analyze competition, recruit talent, and monitor legal trends.
Marketing Agencies – Generate leads from attorney listings and legal networks.
Insurance Companies – Verify legal credentials and case histories.
Related Data Scraping Services
Actowiz Solutions offers a range of web scraping services beyond legal data extraction. Check out our other services:
Extract Stock & Finance Data – Stay ahead in financial markets with real-time data extraction.
Yellow Pages Data Scraping – Collect business leads from directories effortlessly.
Website Price Scraper – Monitor product prices across e-commerce platforms.
Web Scraping News Articles – Extract news updates for media analysis and trend tracking.
Get Started with Lawyer Data Scraping
If you’re looking for reliable and efficient lawyer data scraping services, Actowiz Solutions is here to help. Our cutting-edge tools ensure accurate data extraction tailored to your needs. Contact us today and transform the way you access legal data!
#lawyer data scraping services#Extract Stock & Finance Data#Yellow Pages Data Scraping#Website Price Scraper#Web Scraping News Articles
0 notes
Text
hello fellow comic art fans.
i am the goblin who runs this here blog. otherwise known as @jondoe297
i am extremely bummed that when i do come out and adress the followers of this blog directly it will be with this news. well. here goes:
Comic Art Showcase will indefinitely stop sharing our favorite artists' works until further notice due to the deal tumblr's owner is making with A.I. companies to sell data,enabling the theft of the works of the platform's users to scrape to train their A.I.
and here is a good article about what's going on
while for the over 5 years(!!) now that i have run this page and shared the love of comic art i am so passionate about,through ups and downs,i have kept this page strictly for doing so. not presenting any topics or ideas or even showing my own personality or linking my personal blog(even though i have been flirting with the idea recently. well i guess now is as good a time as any) i feel that if nothing else i have to use this specific platform i have,as it is,to address this topic as it is intrinsic and intertwined with this page's theme or activity. and i will not have it be an open buffet for these greedy corporations to scrape for data to feed the A.I. with which they seek to replace the very artists that i love and admire! even though it may be too late as we don't really know how long they've been doing this. well the inevitable came. and if this page is not deleted it will at least not be posted on for the time being. while we figure out what to do next.
in the meantime we can and have to all do what we can to fight for artists' and creatives' rights. if nothing else by not being a part of the theft and exploitation of them an their work. please do not use any generative A.I. programs for images or text. they work by scraping from databases of artists' and creatives' works without any permission,credit or compensation.
for now we can at least 'opt out' of having our content be shared with the A.I. companies in the settings.
keep in mind this seems to be only available on the web version and not on the app for now!
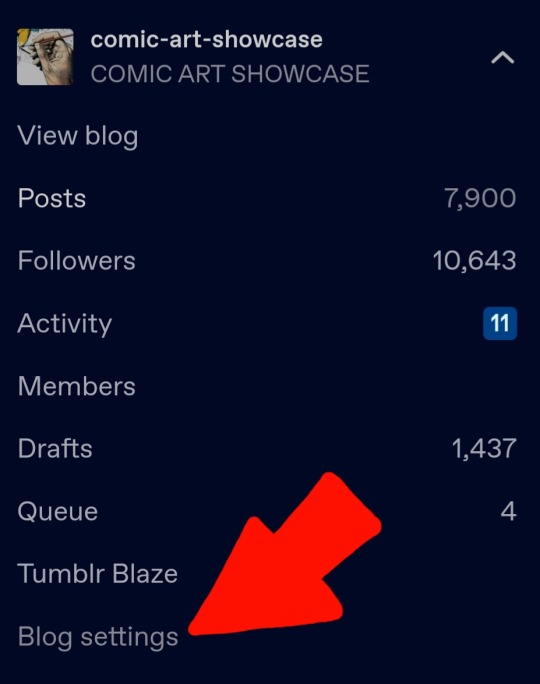
go to your blog settings from the corner here

ID/image description: a screenshot of the tumblr blog with a red arrow pointed at the options button. end description.
then go to 'blog settings'
ID/image description: a screenshot of tumblr blog settings with a red arrow pointing at the 'blog settings' option. end description.
then go to visibility. and turn ON the 'prevent third-party sharing' option. make sure to turn it ON not off.
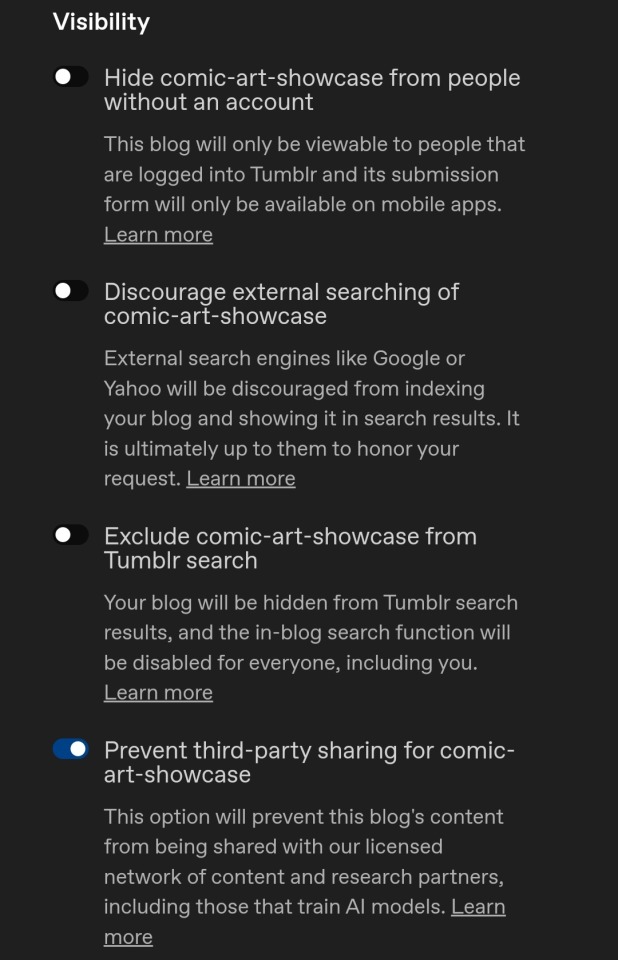
ID/image description: screenshot of tumblr's visibility settings with the 'prevent third-party sharing' option turned on. end description.
and you have to do this for each blog and sideblog individually so make sure to do that!
and artists make sure to use Nightshade and Glaze to protect your artwork and images!!!!
here's a link to Nightshade
here's a link to Glaze
the best combination is to use Nightshade first then Glaze on your images.
Glaze creates a protective layer on the image to prevent A.I. from copying it. while Nightshade poisons the A.I. sotfware.
stay safe friends an i will see you around❤
#comic art#no to ai art#no to ai generated art#no to ai generated images#no to ai#anti ai#artist rights#art news#artists on tumblr#create don't scrape
626 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
246 notes
·
View notes
Note
in what way is it a doomed investment? I've seen a lot of artist lose their jobs to it already, it has had a greater impact than nft's and right now they're going on to make ai video's. I'm sure the bubble will break eventually but, yea share your thoughts.
Here's an article I recommend reading.
We're at the peak of a tech hype cycle. People are absolutely getting hurt and laid off from billions of dollars being poured into the latest money hole that the developers double pinkie prommy will actually work the way they're advertising... at some later date; but I suspect the main staying power for this tech is going to be spam/advertisement generation and disinformation. If you want to provide a quality chat service or make art worth looking at, human intervention is necessary even if you use generative AI as a starting point. While none of this is... good, in the same way NFTs and useless dotcom sites were not good, I am skeptical of a lot of the panic around generative AI replacing humans long term because I think it lends legitimacy to the people claiming it can competently do that.
I also think a lot of the panic around tumblr specifically is kind of redundant. I don't appreciate the site fucking condoning it, but all major social media sites have already been getting fed into these things. There is (currently) no real way to stop these companies from throwing whatever they want off of google into the machine and claiming they totally only use non-copyrighted goods, because they're drawing from billions of images and source texts and there's (currently) no easy way to check besides combing through those massive databases.
Besides, if you publicly post art online, there's already dozens of other websites scraping income off of your work. The social media you use hosts ads, and your art and presence on social media is what draws in new ad viewers and revenue. And there's aggregator sites that draw from and repost stuff from other social media sites, and they host ads. Listacle "news" sites put their top ten favorite web finds on a page covered in ads. Web searches that show your art in a pile of other images host ads. If your art is popular, the number of sites scraping income off of your work grows proportionately. This is my personal opinion, but I'd say AI is a new hat on a commons-exploitation problem that's as almost as old as the internet.
#politics#i also think free social media is going to die in the future so the scraping chain of ad servers may also be doomed but lmao
67 notes
·
View notes
Text
I made this in response to a specific post, but this pretty much applies to everything right now. I wonder if future archivists will have to delineate a before/after ChatGPT to assess how poisoned the data is. People will start using the waybackmachine to read articles written before three-level-of-reference-obscured bullshit fully saturates all knowledge fields.
It’s not just the fact that these bullshit misinformation articles are being put out in the first place. It’s that now that they are out there, other article and news scraping services are going to pick it up to cobble together their own bullshit pages. This will essentially ‘launder’ the misinformation by presenting it as just a logical sounding snippet alongside other scraped facts. Later when you try and figure out the truth, the false info pops up all over too because half the web these days is republishing scraper sites just wanting your eyetime for advertisers (they have zero interest in what they are showing you let alone if it’s true)
So, in the interest of maaaybe getting you to see ten seconds of a banner ad and the resulting .000002 cents, we are actively destroying our knowledge archive
So, feel free to use this image bc unfortunately it is probably just going to get more and more relevant
180 notes
·
View notes
Text
On Rivd and AI
So last night I made this post and said I'd elaborate more in the morning and when I had the time to do a bit of research. Upon doing said research, I realized that I had misunderstood the concerns being raised with the Rivd situation, but that isn't the case any more. However, some of my thoughts on ai still stand. Heads up, this is going to be a long post. Some actual proper blogging for once wow.
I'm going to discuss the Rivd phishing scam, what can be done for fic writers as ai begins to invade fan spaces, and my elaborated thoughts on Language Learning Models. Warning for transparency: I did utilize chat gpt for this post, NOT for the text itself but to provide examples of the current state of LLMs. Some articles I link to will also be ai generated, and their generated quality is part of what I'll be warning about. This is not a generated post and you can tell because I've got those nifty writing things called "voice" and "style."
ANYWAYS:
Okay so what was the Rivd situation? So two days ago this post was uploaded on tumblr, linking back to a twitter thread on the same topic. I saw it late last night because I was traveling. A reddit post was also uploaded 3 days ago. According to google trends, there was a slight uptick in search traffic the week of June 23rd, and a more severe uptick last week (June 30th-July 6th). That's all to say, this website did not exist until last week, caused a stir, and immediately was put down.
Rivd is not longer up. Enough people contacted its web hosting service Cloudflare and they took the site down. This happened yesterday, from the looks of it.
So, then, what was Rivd? And more importantly, what was the point of scraping a chunk of ao3 and re-uploading it? There seems to be 2 possible theories.
1) The more innocent of the two: they genuinely want to be an ao3 competitor. I can't look at the website any more, and very little positive results appear when googled, but I did find one ai-generated puff piece called "Exploring Rivd: The Premier Platform for Movie-Based Fanfiction" posted to Medium last week by one "Steffen Holzmann" (if that is your real name... x to doubt). This account appeared the same week that Rivd had that first little uptick in google queries, so it is undoubtedly made by the people running the website themselves to create an air of legitimacy. Medium appears to be a safe enough website that you can click that link if you really want to, but you shouldn't. It's a bad generated article, there's very little to glean from it. But it is a remnant source on what Rivd was claiming to be, before it was taken down. Here's the conclusion from the article, the only portion that gave any actual information (and it barely offers any):
Rivd is the ultimate platform for movie-based fanfiction, offering a diverse range of content, a supportive community, and robust interactive features. Whether you’re a writer looking to share your work or a reader seeking new adventures in your favorite movie universes, Rivd provides the perfect platform to engage with a passionate and creative community. Start your journey on Rivd today and immerse yourself in the world of fanfiction.
There's a second article by Holzmann titled "Mastering the Art of Fanfiction Writing in 2024" that's essentially similar ai bull, but trades explaining that fans can write Star Wars fic for explaining that you can make OC's and maybe get a beta (not that that's advice I've ever heeded. Beta? Not in this house we don't.) This was posted six days ago and similarly spends half the time jerking Rivd off. That's all to say, if they are to be believed at face value, this website wanted to just be a fic hosting site. Scraping Ao3 would have made it seem like there was already an active user base for anyone they were attempting to attract, like buying your first 50,000 instagram followers. Anyone actually looking to use this as a fic site would have quickly realized that there's no one on it and no actual fan engagement. There's already fan community spaces online. This website offers nothing ao3 or ffn or wattpad or livejournal or tumblr or reddit didn't already.
Similarly, it reeks of tech bro. Between the scraping and the ai articles, the alarms are already going off. According to that Reddit thread, they were based out of Panama, though that doesn't mean much other than an indicator that these are the type of people to generate puff articles and preemptively base their business off-shore. Holzmann, it should be mentioned, also only has 3 followers, which means my tiny ass blog already has more reach than him. Don't go following that guy. The two comments on the first article are also disparaging of Rivd. This plan didn't work and was seen right through immediately.
If fan communities, and those who write fic know anything, it's how to sniff out when someone isn't being genuine. People write fic for the love of the game, at least generally. It's a lot of work to do for free, and it's from a place of love. Ao3 is run on volunteers and donations. If this genuinely is meant to be a business bro website to out-compete ao3, then they will be sorely disappointed to learn that there's no money in this game. It would be short lived anyway. A website like this was never going to work, or if it was, it would need to ban all copyrighted and explicit materials. You know, the pillars of fic.
So then what was the point of all of this? Unless there was a more nefarious plan going on.
2) Rivd was a phishing scam. This is so so so much more likely. The mark for the scam isn't fic readers, it's fic writers. Here's how it works: they scrape a mass of ao3 accounts for their stories, you catch it, you enter a lengthy form with personal info like your full name and address etc. requesting they take your work down, they sell your data. Yes, a lot of personal info is required to take copyrighted materials down on other sites, too. That's what makes it a good scam. Fic already sits in a legal grey area (you have a copyright over your fic but none of the characters/settings/borrowed plot within it. You also CANNOT make money off of fic writing). So the site holds your works ransom, and you can't go to Marvel or Shueisha or fuck it the ghost of Ann Rice herself to deal with this on your behalf. Thankfully, enough people were able to submit valid DMCA's to Cloudflare to deal with the issue from the top.
Remember this resolution for the next time this situation arises (because of course there will be a next time). Go through higher means rather than the site itself. These scams are only getting more bold. Me personally? I'm not going to give that amount of personal info to a website that shady. Be aware of the warning signs for phishing attacks. Unfortunately, a lot of the resources online are still around text/email phishing. We live in a time where there's legal data harvesting and selling, and illegal data harvesting and selling, and the line in between the two is thin and blurry. Here's an FTC article on the signs of phishing scams, but again, it's more about emails.
I should note, I do not think that Rivd is connected to the ransomware virus of the same name that popped up two or three years ago [link is to Rivd page on PCrisk, a cypersecurity/anti-malware website]. It's probably just coincidence.... but even so. A new business priding itself on SEO and all that tech guy crap should know not to name itself the same thing as a literal virus meant to scam out out of a thousand dollars.
That's all to say, this was absolutely a scam meant to take personal info from ao3 writers. And that blows. To love art and writing and creation so much just to have your works held hostage over data feels really bad. Of course it does!
So, should you lock down your ao3 account?
That, to me, is a little trickier. You can do as you please, of course, and you should do what makes you feel safest. Me personally, though, I don't plan on it. I really, really like that guests can interact with my work from the outside. Ao3 still uses an invite system, so a lot of regular users still don't have accounts for any number of reasons. I read a lot of the time logged out anyways. I started writing again last year after all the info on the ao3 Language Learning Model training had already come out. Like I talked about in my last post, I set out to write things that a computer couldn't produce. (from here on out, I'm going to be using One Piece fic as an example, simply because that's what I write. It's also in a really prime position for a lot of ai discussion due to the size of the fandom and the size of the original work)
I'm going to be honest, I'm not all that afraid of my work being scraped for LLMs to train off of. Text generators have existed for a decade now, but they really popped off last year. LLM's are at a point, though, where the tech is sort of stagnating after the initial boom. The flaws of current ai chat bots are so baked into the flaws of ai itself that they won't be ironed out soon. They make up info, they're easily manipulated, they simply are not people. The flaw here is deep- you can trace it to the fact that we don't know enough about neuroscience itself, and even then neuroscientists don't make ai. Ai programers do. Complex info already has to make one synaptic jump without losing any understanding from person to person, and then it has to be perfectly abstracted for a machine to comprehend. It can't be done with the tools we currently have. I DO hate to admit it, but there are some decent uses for ai. if you are specifically a python programmer. The rest of us? Maybe not.
I don't like generated fic, I don't read it on principle. Checking on ao3, though, there's only 4 total generated op fics (3 in spanish, one in english, 3 xreader, 1 zosan but 2nd person zosan? and the author edited the framework the computer generated text. I still didn't enjoy the fic, tho.) But that breaks down to .005% of all op fics. I went into chat gpt and asked it to generate a drabble for me based on One Piece, and this is what it wrote:

[Image ID: A screenshot of chat GPT. The first line shows my prompt. It reads: You- write me a short 100 word fanfiction based on the manga One Piece. Next line, Chat GPT- "On the shores of an uncharted island, the Straw Hat Pirates stumbled upon a hidden treasure trove. Among the glittering gold and jewels, Luffy discovered an old, weathered journal. Inside, he found sketches and notes detailing the adventures of a legendary pirate who once roamed the Grand Line. Excited by the prospect of a new adventure, the crew set sail. following clues left in the journal. Along the way, they faced formidable foes and forged new alliances, unraveling the mysteries of the lost pirate's legacy. With each island they conquered, they grew closer to uncovering the ultimate treasure- a legacy that would shape their own journey." End ID]
Okay so like, this blows, yeah? 75,000 One Piece fics to train off of on ao3 and it still can't like, write a decent little story. This reads more like an episode summary or a book dust jacket blurb. Drabbles have an internal structure that make them interesting, much like a single sentence short story. You have to get very baby shoes never worn with them, yeah? Ai doesn't understand that, it just knows how many words it has to generate. It doesn't have any sense for creative language, metaphor, simile, poetry. I asked it to write me a poem and it wrote me the same poem with thesaurus replacements each time it re-generated one. A lot about dreams and stars and midnight and whispers, over and over again. The same rhyme scheme and cadence too.
It's also- vitally- so unhorny that it's almost a crime. For a test, I asked it to generate a story about a uhhhhh robot and an archeologist kissing. Just to see what it would give me. I ran 4 tests, a robot falling in love with an archeologist, a robot kissing an archeologist, an archeologist kissing a robot, and an archeologist falling in love with a robot. All 4 were incredibly chaste, quiet little drabbles about the innocence of discovery or whatever the fuck. Here's one of them:

[Image ID: A screenshot of chat GPT. The first line shows my prompt. It reads: You- write me a short 100 word story about an archeologist kissing a robot. Next line, Chat GPT- "Int he dimly lit chamber, Professor Evelyn Porter stared in awe at the ancient artifact- a remarkably lifelike robot buried for millennia. As she leaned closer to examine its intricacies, a surge of curiosity and admiration swept over her. In a moment of spontaneous fascination, she brushed her lips against the cool metal of its cheek, a gesture of reverence and connection across ages. The robot, dormant for eons, stirred faintly in response to the unexpected contact. It was fleeting, almost surreal exchange between past and future, bridging the gap between human exploration and technological marvels of ancient civilizations." End ID]
So like, some of these phrases gets to what's vaguely intriguing about this dynamic, sure. But at the end of the day it's still uhhhh chaste as hell. A reverent kiss??? Not what I want in my fic!!!! This is all to say, LLM's can scrape ao3 all they want, that doesn't mean they can USE what they're stealing. The training wheels have to stay on for corporate palatability. I'm stealing, I'm taking these dolls out of Shueisha's grubby hands and I'm making them sexy kiss for FREE.
In my opinion, the easiest way to keep your work out of the hands of ai is to write something they cannot use. If the grey area of copyright lies in how much is transformed, then motherfucking TRANSFORM it. Write incomprehensible smut. Build surreal worlds. Write poems and metaphors and flush out ideas that a computer could never dream of. Find niches. Get funky with it. Take it too far. and then take it even farther. Be a little freaking weirdo, you're already writing fic so then why be normal about it, you know? Even if they rob you, they can't use it. Like fiber in the diet, undigestible. Make art, make magic.
Even so, I don't mind if the computer keeps a little bit of my art. If you've ever read one of my fics, and then thought about it when you're doing something else or listening to a song or reading a book, that means something I made has stuck with you just a little bit. That;'s really cool to me, I don't know you but I live in your brain. I've made you laugh or cry or c** from my living room on the other side of the world without knowing it. It's part of why I love to write. In all honesty, I don't mind if a computer "reads" my work and a little bit of what I created sticks with it. Even if it's more in a technical way.
Art, community, fandom- they're all part of this big conversation about the world as we experience it. The way to stop websites like Rivd is how we stopped it this week. By talking to each other, by leaning on fan communities, by sending a mass of DMCA's to web host daddy. Participation in fandom spaces keeps the game going, reblogging stuff you like and sending asks and having fun and making art is what will save us. Not to sound like a sappy fuck, but really caring about people and the way we all experience the same art but interpret it differently, that's the heart of the whole thing. It's why we do this. It's meant to be fun. Love and empathy and understanding is the foundation. Build from there. Be confident in the things you make, it's the key to having your own style. You'll find your people. You aren't alone, but you have to also be willing to toss the ball back and forth with others. It takes all of us to play, even if we look a little foolish.
#meta#fandom#fanfic#ao3#again i put this in my last post but this is JUST about LLMs#ai image generation is a whole other story#and also feel free to have opposing thoughts#i'm total open to learning more about this topic#LONG post
25 notes
·
View notes
Text
Kashmir Hill’s “Your Face Belongs to Us”

This Friday (September 22), I'm (virtually) presenting at the DIG Festival in Modena, Italy. That night, I'll be in person at LA's Book Soup for the launch of Justin C Key's "The World Wasn’t Ready for You." On September 27, I'll be at Chevalier's Books in Los Angeles with Brian Merchant for a joint launch for my new book The Internet Con and his new book, Blood in the Machine.

Your Face Belongs To Us is Kashmir Hill's new tell-all history of Clearview AI, the creepy facial recognition company whose origins are mired in far-right politics, off-the-books police misconduct, sales to authoritarian states and sleazy one-percenter one-upmanship:
https://www.penguinrandomhouse.com/books/691288/your-face-belongs-to-us-by-kashmir-hill/
Hill is a fitting chronicler here. Clearview first rose to prominence – or, rather, notoriety – with the publication of her 2020 expose on the company, which had scraped more than a billion facial images from the web, and then started secretly marketing a search engine for faces to cops, spooks, private security firms, and, eventually, repressive governments:
https://www.nytimes.com/2020/01/18/technology/clearview-privacy-facial-recognition.html
Hill's original blockbuster expose was followed by an in-depth magazine feature and then a string more articles, which revealed the company's origins in white nationalist movements, and the mercurial jourey of its founder, Hoan Ton-That:
https://www.nytimes.com/interactive/2021/03/18/magazine/facial-recognition-clearview-ai.html
The story of Clearview's technology is an interesting one, a story about the machine learning gold-rush where modestly talented technologists who could lay hands on sufficient data could throw it together with off-the-shelf algorithms and do things that had previously been considered impossible. While Clearview has plenty of competitors today, as recently as a couple of years ago, it played like a magic trick.
That's where the more interesting story of Clearview's founding comes in. Hill is a meticulous researcher and had the benefit of a disaffected – and excommunicated – Clearview co-founder, who provided her with masses of internal communications. She also benefited from the court documents from the flurry of lawsuits that Clearview prompted.
What emerges from these primary sources – including multiple interviews with Ton-That – is a story about a move-fast-and-break-things company at the tail end of the forgiveness-not-permission era of technological development. Clearview's founders are violating laws and norms, they're short on cash, and they're racing across the river on the backs of alligators, hoping to reach the riches on the opposite bank without losing a leg.
A decade ago, they might have played as heroes. Today, they're just grifters – bullshitters faking it until they make it, lying to Hill (and getting caught out), and the rest of us. The founders themselves are erratic weirdos, and not the fun kind of weirdos, either. Ton-That – who emigrated to Silicon Valley from Australia as a teenager, seeking a techie's fortune – comes across as a bro-addled dimbulb who threw his lot in with white nationalists, MAGA Republicans, Rudy Guiliani bagmen, Peter Theil, and assorted other tech-adjascent goblins.
Meanwhile, biometrics generally – and facial recognition specifically – is a discipline with a long and sordid history, inextricably entwined with phrenology and eugenics, as Hill describes in a series of interstitial chapters that recount historical attempts to indentify the facial features that correspond with criminality and low intelligence.
These interstitials are woven into a-ha moments from Clearview's history, in which various investors, employees, hangers-on, competitors and customers speculate about how a facial-recognition system could eventually not just recognize criminals, but predict criminality. It's a potent reminder of the AI industry's many overlaps with "race-science" and other quack beliefs.
Hill also describes how Clearview and its competitors' recklessness and arrogance created the openings for shrewd civil libertarians to secure bipartisan support for biometric privacy laws, most notably Illinois' best-of-breed Biometric Information Privacy Act:
https://www.ilga.gov/legislation/ilcs/ilcs3.asp?ActID=3004&ChapterID=57
But by the end of the book, Hill makes the case that Ton-That and his competitors have gotten away with it. Facial recognition is now so easy to build that – she says – we're unlikely to abolish it, despite all the many horrifying ways that FR could fuck up our societies. It's a sobering conclusion, and while Hill holds out some hope for curbing the official use of FR, she seems resigned to a future in which – for example – creepy guys covertly snap photos of women on the street, use those pictures to figure out their names and addresses, and then stalk and harass them.
If she's right, this is Ton-That's true legacy, and the legacy of the funders who handed him millions to spend building this. Perhaps someone else would have stepped into that sweaty, reckless-grifter-shaped hole if Ton-That hadn't been there to fill it, but in our timeline, we can say that Ton-That was the bumbler who helped destroy something precious.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/09/20/steal-your-face/#hoan-ton-that
#pluralistic#books#reviews#gift guide#clearview ai#facial recognition#biometrics#eugenics#crime#privacy#cop shit#hoan ton-that
85 notes
·
View notes
Text

@thwipsthrown asked: “How’d you get a black eye?” (e17 gwen to e17 peter?)
------

"Will you promise not to laugh at me?"
The black eye in question, along with the scrapes and cuts that had already healed up like they were never there, was from that morning. When some guys from one of the local crime families decided to storm into the courthouse and take one of the halls hostage, refusing to let anyone go until three people from their ranks were released. With the added comment of proving to New York once and for all that they were the ones who ran the city, not the supposed Kingpin that no one could even prove existed. One of them happened to get a lucky shot with the end of his gun and pegged Peter right in the eye before he got the hostages out and the ones responsible webbed up.
Naturally, there were now three new conspiracy articles, two of which were published by The Daily Bugle, about if Spider-Man was a new enforcer for the mythic crime ruler of New York, and that was why he spent so much time fighting other guys and not taking down his new "boss".
"I was trying to load my bag back up with my books getting to my next class and managed to avoid the other people leaving the building but not the large, obvious metal pole between the doors on the way out. Seriously like ten people witnessed this, I'm debating dropping the class just to avoid them bringing it up next lecture." he lied, tone remorseful and scrunching up his face in an embarrassed wince. A twinge of guilt flaring at the cover but it was a lot better than claiming he was jumped and mugged like he did two months ago, "....please don't text Harry and MJ about it? I want to enjoy the last shreds of my dignity after this one for a little longer."
3 notes
·
View notes
Text
📊 Unlocking Trading Potential: The Power of Alternative Data 📊
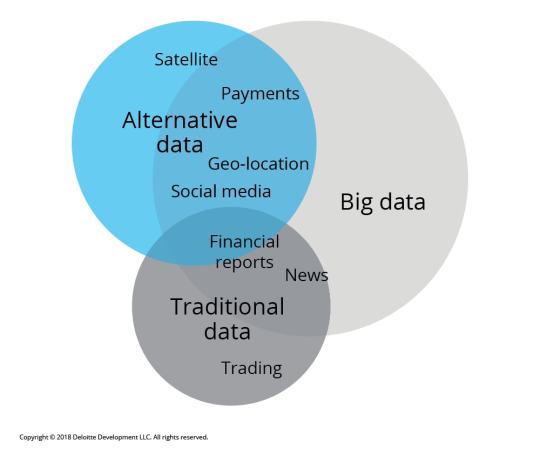
In the fast-paced world of trading, traditional data sources—like financial statements and market reports—are no longer enough. Enter alternative data: a game-changing resource that can provide unique insights and an edge in the market. 🌐
What is Alternative Data? Alternative data refers to non-traditional data sources that can inform trading decisions. These include:
Social Media Sentiment: Analyzing trends and sentiments on platforms like Twitter and Reddit can offer insights into public perception of stocks or market movements. 📈
Satellite Imagery: Observing traffic patterns in retail store parking lots can indicate sales performance before official reports are released. 🛰️
Web Scraping: Gathering data from e-commerce websites to track product availability and pricing trends can highlight shifts in consumer behavior. 🛒
Sensor Data: Utilizing IoT devices to track activity in real-time can give traders insights into manufacturing output and supply chain efficiency. 📡
How GPT Enhances Data Analysis With tools like GPT, traders can sift through vast amounts of alternative data efficiently. Here’s how:
Natural Language Processing (NLP): GPT can analyze news articles, earnings calls, and social media posts to extract key insights and sentiment analysis. This allows traders to react swiftly to market changes.
Predictive Analytics: By training GPT on historical data and alternative data sources, traders can build models to forecast price movements and market trends. 📊
Automated Reporting: GPT can generate concise reports summarizing alternative data findings, saving traders time and enabling faster decision-making.
Why It Matters Incorporating alternative data into trading strategies can lead to more informed decisions, improved risk management, and ultimately, better returns. As the market evolves, staying ahead of the curve with innovative data strategies is essential. 🚀
Join the Conversation! What alternative data sources have you found most valuable in your trading strategy? Share your thoughts in the comments! 💬
#Trading #AlternativeData #GPT #Investing #Finance #DataAnalytics #MarketInsights
2 notes
·
View notes
Text
De-Program The Algorithm: RSS is good and you should be using it.
Escape the algorithm, tune your feed and save the world; or, even though it's old and ugly, RSS can make your life better.
We live in a time of algorythmic feeds that distort our perceptions of events, time, and the people that we care about. Non-stop, hardwired access by large corporations into the pleasure centers of our brains have disrupted human congnition to the point where many wonder how we ever found content we liked without having it served up by angelic machines that live in the cloud, accessing us via the little magic boxes that live in our pockets.
There IS a way out of it, though, and it comes from before Web 1.0. It is called RSS, or Real Simple Syndication.
A more thorough explanation under the jump!
In the even older times, Syndication was a word used by old media to describe an article or show that they'd gotten from somewhere else, and were presenting as content to their own viewers. Star Trek, Garfield, and millions of other comics, stories, TV shows found success not in their initial markets, but in the long running and carefully tuned presentation of existing backlogs to interested audiences.
While syndication was previously a method of showing old content to new audiences, RSS is primarily a method of displaying new content in a feed to an audience of one, or a few. You can set your RSS up to have as much or as little content as you wish, mindlessly scraping vast quantities of podcasts and articles, or as a carefully pruned garden, where each entry lives or dies by the pleasure it brings you.
You can even put porn on it. And webcomics.
Youtube is compatible, which means you could bypass any artificial limiting our curation of your subscription tab with it. Tumblr blogs can be RSS feeds as well, as well as most wordpress sites. RSS is usually a defacto afterthought in this day and age, but sites like twitter don't work natively (Thanks Elon).
Really, the biggest killer for me is that I can create not just a video subscription feed that actually shows all of my subscriptions, I can even create several feeds of content based on genre or subject. No longer will my miniature painting videos be swept away in a tide of tech reviews or drama alerts!
There are self hosted options if you have a server or an unemployed raspberry pi, but for the general user, I highly recommend browser plugins like Feedbro, or apps like Feedly. Many of them have paid features now, but don't be fooled. There is always a free way to get your feed set up, and Feedbro works on mobile anyway. Sadly, this isn't something that firefox can sync, but at least you can export your desktop feed and import it on mobile.
#technology#rss#web 1.0#old internet#algorithm#jake wrote a blog#Seriously fuck youtube though. This is how you de-program the algorithim.
5 notes
·
View notes
Text
Algorithm is not a bad word
Named for Arabic mathematician al-Khwarizmi and partially formalized by queer mathematician Alan Turing, algorithms are simply a process for doing things, potentially with a desired result.
An early algorithm we learn in school is how to add two whole numbers together. Using pencil and paper, you can probably figure out what 420 + 69 is. In fact there are multiple ways. You could draw out 420 dots, draw another 69 dots, and count how many there are in total. Or you could lay them vertically, start at the ones column, and compute the digits of the sum.
Algorithms are not strictly related to numbers. What if you’re a teacher and you want to sort homework assignments alphabetically by the students’ names? Well you’ll probably have a process, which involves checking repeatedly if two pieces of homework are out of order (e.g. if you had homework from Bob then homework from Alice, you would swap the two since Alice is first alphabetically).
Another great non-numerical example of algorithms is solving the Rubik’s Cube and it’s larger variants. In the cube solving community, there are algorithms for specific processes, such as rotating corners cubies or flipping edge cubies. Some of these apply to the 3x3x3 cube, others can be generalized to help one solve a 69x69x69 cube.
Algorithms are also beautiful. Visualizing how the data dances around can be incredible. Check out this animation from Wikipedia showing the Heapsort algorithm in action:

This inspired the hell outta me when I first saw it in 2007. That diagram a couple seconds in, where it just sounds like it’s emitting a thunky beep at ya before suddenly just putting everything together. The way there’s sort of a pattern before it. Just that sheer magic.
You can also make art out of algorithms. From my username, one of my favorite categories is maze generation algorithms. Think Labyrinth, whose algorithm page I just linked, was an early website I found on the Internet, and I’m so happy it has survived the various eras of web evolution. The Maze of Theseus in particular was a huge inspiration for me after printing it out in 2000 on a summer road trip.

Alas Think Labyrinth is from before the days of heavy animations on the Internet, so to visualize a maze algorithm I will instead link to Mike Bostock’s article on Visualizing Algorithms. It includes many dynamic animations that are rendered in your browser, including the sorting algorithms and maze generation algorithms mentioned above, among many others.
So why the hate for algorithms?
On Tumblr in the past few days, and more generally social media in the past decade, we recently saw favoritism for sorting algorithms that allow us to view our feeds in chronological order. Many claimed they were opposed to an algorithm that decided in a corporate-specific manner what we should see first. Let me be clear: the corporate ordering of a feed is bad, but it is not bad because it’s an algorithm. It’s bad because it’s not one of the algorithms that users want for ordering their feed.
The other negative use case grew heavily in the past 15 years: algorithms that are “trained” on biased and/or unethically obtained data. We’ve seen many examples of systems that were trained on data sets of white college students such as facial recognition technology, which then later gets implemented at a large scale and fucks over people of color. The past couple years we’ve seen a rise in creating data sets based on scraping millions of artists’ works without any permission from the artists themselves*. Either of these applied to a corporate or government scale leads to active harm to populations already at risk and probably some new ones too.
Finally, we’ve seen a rise in computer automation for things that should be done by people. I can’t find the specifics, but this quote is allegedly from a 1979 IBM presentation:
A computer can never be held accountable, therefore a computer must never make a management decision.
My first thought on where this comes up is applying for jobs. Many companies will use a poorly thought out algorithm to filter through job applications, simply scanning for a couple key words they want (programmers who know Vulkan or Node.js) or more maliciously looking for words they don’t want (needing any kind of accommodation, sounding too anti-capitalist, etc). These algorithms cannot be held accountable and should not be involved in any stage of the hiring process.
Quick aside: When I was searching for the source of that quote about accountability, I typed in the first half in Google, and the autocomplete was

Fucking modern Google.
Some concluding thoughts
I like algorithms. They are a passion of mine. When people say algorithms are evil, I’m sad. When people recognize the usage of certain algorithms in certain contexts are evil, I’m more happy (yet still disturbed these things happen). I just really wanted to educate people on the usage of the word.
Also, algorithms are not about Al Gore’s dance moves. Please stop with that stupid fucking joke.
*I mentioned scraping data from millions of images without permission of the creators. My one iffy status with this is how sort of applies to the human brain doing a similar process over the span of one’s life. What is it that separates my looking through a book of Escher’s works from a computer looking at it?
Obviously many things, but I’m horrendous as philosophy and ethics, so I’m just gonna stay in my comfort zone of pure algorithms and try not to get too involved. Experts can figure out a more formal definition for what I can only describe as a gut feeling.
13 notes
·
View notes
Text
Zoom, the company that normalized attending business meetings in your pajama pants, was forced to unmute itself this week to reassure users that it would not use personal data to train artificial intelligence without their consent.
A keen-eyed Hacker News user last week noticed that an update to Zoom’s terms and conditions in March appeared to essentially give the company free rein to slurp up voice, video, and other data, and shovel it into machine learning systems.
The new terms stated that customers “consent to Zoom’s access, use, collection, creation, modification, distribution, processing, sharing, maintenance, and storage of Service Generated Data” for purposes including “machine learning or artificial intelligence (including for training and tuning of algorithms and models).”
The discovery prompted critical news articles and angry posts across social media. Soon, Zoom backtracked. Soon, Zoom backtracked. On Monday, Zoom’s chief product officer, Smita Hasham, wrote a blog post stating, “We will not use audio, video, or chat customer content to train our artificial intelligence models without your consent.” The company also updated its terms to say the same. Later in the week, Zoom updated its terms again, to clarify to say that it would not feed "audio, video, chat, screen sharing, attachments, or other communications like customer content (such as poll results, whiteboard, and reactions)" to AI models. Vera Ranneft, a spokesperson for the company, says Zoom has not previously used customer content this way.
Those updates seem reassuring enough, but of course many Zoom users or admins for business accounts might click “OK” to the terms without fully realizing what they’re handing over. And employees required to use Zoom may be unaware of the choice their employer has made. One lawyer notes that the terms still permit Zoom to collect a lot of data without consent.
The kerfuffle shows the lack of meaningful data protections at a time when the generative AI boom has made the tech industry even more hungry for data than it already was. Companies have come to view generative AI as a kind of monster that must be fed at all costs—even if it isn’t always clear what exactly that data is needed for or what those future AI systems might end up doing.
The ascent of AI image generators like DALL-E 2 and Midjourny, followed by ChatGPT and other clever-yet-flawed chatbots, was made possible thanks to huge amounts of training data—much of it copyrighted—that was scraped from the web. And all manner of companies are currently looking to use the data they own, or that is generated by their customers and users, to build generative AI tools.
Zoom is already on the generative bandwagon. In June, the company introduced two text-generation features for summarizing meetings and composing emails about them. Zoom could conceivably use data from its users’ video meetings to develop more sophisticated algorithms. These might summarize or analyze individuals’ behavior in meetings, or perhaps even render a virtual likeness for someone whose connection temporarily dropped or hasn’t had time to shower.
The problem with Zoom’s effort to grab more data is that it reflects the broad state of affairs when it comes to our personal data. Many tech companies already profit from our information, and many of them like Zoom are now on the hunt for ways to source more data for generative AI projects. And yet it is up to us, the users, to try to police what they are doing.
“Companies have an extreme desire to collect as much data as they can,” says Janet Haven, executive director of the think tank Data and Society. “This is the business model—to collect data and build products around that data, or to sell that data to data brokers.”
The US lacks a federal privacy law, leaving consumers more exposed to the pangs of ChatGPT-inspired data hunger than people in the EU. Proposed legislation, such as the American Data Privacy and Protection Act, offers some hope of providing tighter federal rules on data collection and use, and the Biden administration’s AI Bill of Rights also calls for data protection by default. But for now, public pushback like that in response to Zoom’s moves is the most effective way to curb companies’ data appetites. Unfortunately, this isn’t a reliable mechanism for catching every questionable decision by companies trying to compete in AI.
In an age when the most exciting and widely praised new technologies are built atop mountains of data collected from consumers, often in ethically questionable ways, it seems that new protections can’t come soon enough. “Every single person is supposed to take steps to protect themselves,” Haven says. “That is antithetical to the idea that this is a societal problem.”
10 notes
·
View notes
Text
Cakelin Fable over at TikTok scraped the information from Project N95 a few months ago after Project N95 announcing shutting down December 18, 2023 (archived copy of New York Times article) then compiled the data into an Excel spreadsheet [.XLSX, 18.2 MB] with Patrick from PatricktheBioSTEAMist.
You can access the back up files above.
The webpage is archived to Wayback Machine.
The code for the web-scraping project can be found over at GitHub.
Cakelin's social media details:
Website
Beacons
TikTok
Notion
Medium
Substack
X/Twitter
Bluesky
Instagram
Pinterest
GitHub
Redbubble
Cash App
Patrick's social media details:
Linktree
YouTube
TikTok
Notion
Venmo
#Project N95#We Keep Us Safe#COVID-19#SARS-CoV-2#Mask Up#COVID is not over#pandemic is not over#COVID resources#COVID-19 resources#data preservation#web archival#web scraping#SARS-CoV-2 resources#Wear A Mask
2 notes
·
View notes
Text
Tumblr to Sell User Content to OpenAI and Midjourney
Based on internal documentation and communications leaked to the news website 404 Media, Tumblr has reached an agreement with Midjourney and OpenAI to sell user-generated Tumblr content to them for use in training their AI models: link.
Tumblr has not officially announced this yet, but after 404 Media’s article (login wall, full article text here) was published, @staff released a statement saying that you can turn off sharing your Tumblr data with third parties, including Tumblr partners and AI companies, via a toggle in your blog settings. Instructions for doing that are here. Note that this is a per-blog setting, so you’ll need to do it for your main blog and any sideblogs you have.
It’s worth noting both OpenAI and Midjourney have probably already used Tumblr data to train their models. Both companies make use of the LAION dataset, which is a huge set of data scraped from the internet by a Germany nonprofit organization, and LAION was scraping the web long before AI started making headlines.
From that angle, this still isn’t great, but it’s also not the end of the world. Agreements like what Tumblr and Midjourney/OpenAI have ostensibly reached will pipe new Tumblr data to them directly on an ongoing basis, but at least now we will have the ability to control this for our blogs (~theoretically~), unlike the secret scraping that LAION was doing.
Unfortunately there is probably no way to delete any data of yours that was already scraped; my understanding is that metadata like which user it was scraped from are generally stripped out of training datasets because they aren’t useful, so there’s no way to identify which data was scraped from which blog etc. Now that tumblr will be sending them the data directly, I’m hopeful that that metadata will be retained so that opt-out requests can be respected in the future. We shall see.
2 notes
·
View notes
Text
The Fascinating Rivalry Between ChatGPT and Elon Musk's AI Grok

In the realm of artificial intelligence, the recent buzz is all about the rivalry between OpenAI's ChatGPT and Elon Musk's AI model Grok. This competition not only showcases the rapid advancements in AI but also opens a dialogue about the future of technology in our lives. Let's delve into the intricacies of this rivalry and what it means for the AI industry. The Genesis of Grok and Its Comparison with ChatGPT https://twitter.com/ChatGPTapp/status/1733569316245930442 Grok, developed under Musk's guidance, represents a new wave in AI technology. It stands in direct competition with OpenAI's ChatGPT, a platform renowned for its conversational abilities and diverse applications. What sets Grok apart is its integration with real-time data, particularly through social media platforms, unlike the basic version of ChatGPT, which relies on data only up to 2023. The Clash Over Common Responses The rivalry took an intriguing turn when ChatGPT highlighted a case where Grok responded to a prompt with an almost identical answer to that of ChatGPT, even mentioning OpenAI. This incident reignited discussions about whether Grok was trained on OpenAI's code, a claim Musk has consistently denied. In response, Musk suggested that the similarity in responses could be due to ChatGPT scraping data from Grok's platform for training purposes. This allegation adds another layer of complexity to the ongoing debate about data usage and intellectual property in the AI domain. Musk's Engagement with Grok's Feedback https://twitter.com/linasbeliunas/status/1733547217649127598 Musk's active involvement in Grok's development and his response to public feedback, both positive and negative, is noteworthy. He has been seen reacting to user comments about Grok on social media, sometimes with humor, indicating his serious investment in the platform's success. https://aieventx.com/elon-musk-pits-chat-gpt-against-grok-in-an-ai-duel-over-the-trolley-problem/ Differing Functionalities and Access to Information A significant difference between ChatGPT and Grok lies in their access to information. While ChatGPT requires a subscription to access real-time data, Grok reportedly has this feature inherently, thanks to its integration with social media data. The Controversy and Clarifications The controversy regarding Grok's data sources led to a statement from Igor Babuschkin, an X user affiliated with xAI. He explained that the similarities in responses might have occurred because Grok inadvertently picked up ChatGPT outputs while being trained on a vast array of web data. He reassured that no OpenAI code was used in Grok's development, emphasizing the rarity of such incidents and promising rectifications in future versions. Broader Implications in the AI Race This rivalry between ChatGPT and Grok exemplifies the broader competition in the AI industry, where big tech companies vie to outperform each other. It raises questions about the ethics of AI development, data privacy, and the potential for AI models to inadvertently overlap in their learning processes. The Future of AI: OpenAI and Musk's Vision As AI continues to evolve, the direction taken by platforms like ChatGPT and Grok will significantly influence the industry's trajectory. Musk's vision for Grok and OpenAI's ongoing innovations with ChatGPT are shaping a future where AI is not only more integrated into our daily lives but also more contentious in terms of its development and application. Conclusion The rivalry between ChatGPT and Grok is more than a technological competition; it is a reflection of the dynamic and sometimes tumultuous nature of AI evolution. As these platforms continue to grow and adapt, they will undoubtedly shape the landscape of AI, posing new challenges and opening up unprecedented possibilities in the realm of artificial intelligence.

Read the full article
3 notes
·
View notes
Text
This day in history

#15yrsago Dead cell-phones: suspense movie cop-outs https://www.youtube.com/watch?v=XIZVcRccCx0
#15yrsago 1.7 sextillion dollar suit filed against B of A https://www.loweringthebar.net/2009/09/bank-of-america-sued-for-1784-sextillion-dollars.html
#15yrsago National Organization for Women backs Net Neutrality https://web.archive.org/web/20090928071029/http://www.capwiz.com/now/issues/alert/?alertid=14084686
#10yrsago MGM shuts down volunteer “Rocky” charity run https://www.techdirt.com/2014/09/24/citizen-organizing-small-get-together-rocky-run-sent-cd-mgm-because-course-she-was/
#10yrsago Class war meets the War on General Purpose Computers https://memex.craphound.com/2014/09/25/class-war-meets-the-war-on-general-purpose-computers/
#10yrsago Monster Manual: bestiaries from 16th Century/1977/2014 https://religiondispatches.org/monstrous-futures-dungeons-dragons-harbinger-of-the-none-generation-turns-40/
#5yrsago Lynda Barry is a Macarthur “genius” https://memex.craphound.com/2019/09/25/lynda-barry-is-a-macarthur-genius/
#5yrsago Thomas Cook travel collapsed and stranded 150,000 passengers, but still had millions for the execs who tanked it https://www.reuters.com/article/us-thomas-cook-grp-passengers-idUSKBN1W90HO/
#5yrsago Stargazing: Jen Wang’s semi-autobiographical graphic novel for young readers is a complex tale of identity, talent, and loyalty https://memex.craphound.com/2019/09/25/stargazing-jen-wangs-semi-autobiographical-graphic-novel-for-young-readers-is-a-complex-tale-of-identity-talent-and-loyalty/
#1yrago How To Think About Scraping https://pluralistic.net/2023/09/25/deep-scrape/#steering-with-the-windshield-wipers

This week, Tor Books published SPILL, a new, free LITTLE BROTHER novella about oil pipelines and indigenous landback!

8 notes
·
View notes